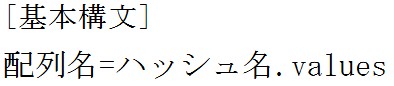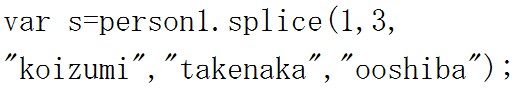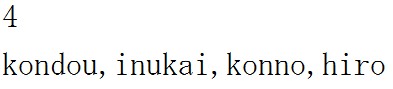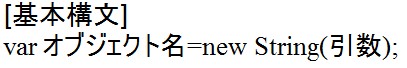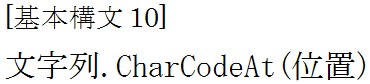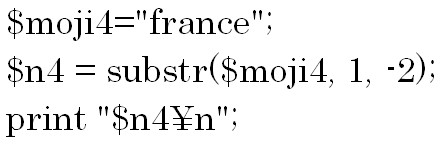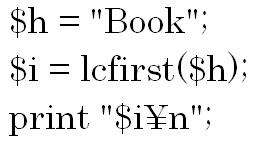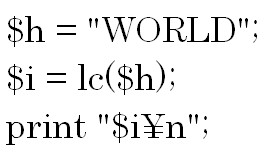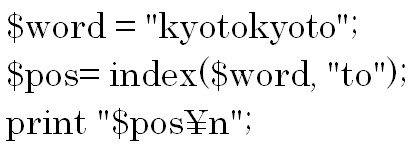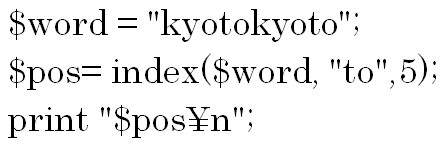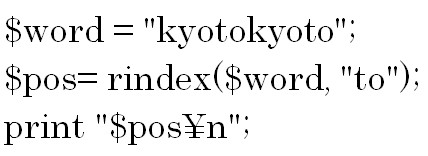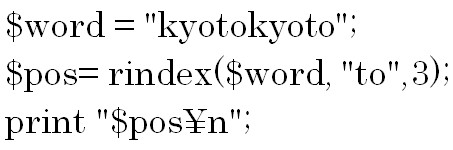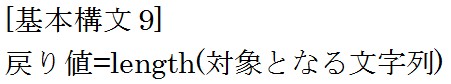この章ではstring(文字列)クラスについて説明します。
今まではダブルクォートやシングルクォートを付けた文字列を扱ってきましたが、これらはstringクラスのオブジェクトです。
「”犬 “」という文字列は![]() と書いても同じ意味になります。
と書いても同じ意味になります。
ここからはstringクラスに関する便利な機能について説明します。
初めに文字列のサイズを取得する方法について説明します。
例をみてみましょう。 「文字列.length」と言う形式で日本語や半角英数字や全角英数字などのサイズ(文字数)を取得できます。
「文字列.length」と言う形式で日本語や半角英数字や全角英数字などのサイズ(文字数)を取得できます。
この例の結果は上から「5」と「8」です。
バイト数を取得したい場合は![]() と言う形式で取得します。
と言う形式で取得します。
では例をみてみましょう。

次はsplitメソッドについて説明します。
では例をみてみましょう。
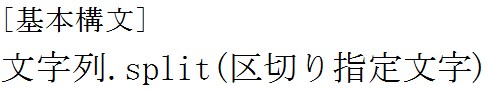 文字列を特定の文字で分割して配列にします。
文字列を特定の文字で分割して配列にします。
区切り指定文字は配列には入りません。
この例は文字列を![]() で区切って、それを配列にします。
で区切って、それを配列にします。
結果は![]() という配列を出力します。
という配列を出力します。
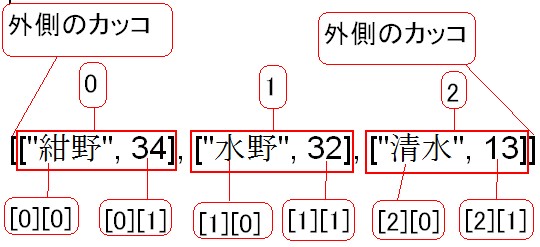
次の例をみてみましょう。 文字列の中身を1文字ずつ配列で取り出したい場合は
文字列の中身を1文字ずつ配列で取り出したい場合は![]() と、記述します。
と、記述します。
結果は![]() です。
です。
次の例をみてみましょう。 第二引数(先頭から2つ目の引数)は文字列を何個の要素に分割したいかを記述します。
第二引数(先頭から2つ目の引数)は文字列を何個の要素に分割したいかを記述します。
変数aの文字列は![]() という文字列で一部構成されていますが、これはカラ文字を意味しています。
という文字列で一部構成されていますが、これはカラ文字を意味しています。
カラ文字も含めて分割したい場合は第2引数をマイナス指定します。
![]() でもマイナスであれば何でもいいです。
でもマイナスであれば何でもいいです。
この例の結果は![]() です。
です。
このカラ文字を分割時に削除したい場合はsplitメソッドの第 2引数に0を指定してください。
もしくは![]() と、0を付けなくてもいいです。
と、0を付けなくてもいいです。
結果は![]() です。
です。
次の例をみてみましょう。 文字列を2つの要素を持つ配列にしたいのであれば第2引数には2を指定します。
文字列を2つの要素を持つ配列にしたいのであれば第2引数には2を指定します。
結果は![]() です。
です。
「”猫”」と![]() の2つに分割されています。
の2つに分割されています。 次は文字列から要素を取り出したり、文字列の要素に新たな要素をセットする方法について説明します。
次は文字列から要素を取り出したり、文字列の要素に新たな要素をセットする方法について説明します。
では例をみてみましょう。
![]() と言う形式で指定するとそれに応じた文字列が取得できます。
と言う形式で指定するとそれに応じた文字列が取得できます。
添え字は一番前が0で次が![]() と数えます。
と数えます。
これは配列の添え字と考え方は一緒です。
この例の結果は「s」です。
その他の例をみてみましょう。 日本語でも同じく使用できます。
日本語でも同じく使用できます。
結果は「あ」です。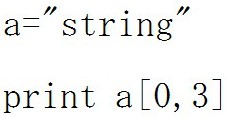 第 2引数を指定すると取り出す個数を指定できます。この例の場合は0番目の添え字から3個取り出すと言う意味になりますので、結果は「str」です。
第 2引数を指定すると取り出す個数を指定できます。この例の場合は0番目の添え字から3個取り出すと言う意味になりますので、結果は「str」です。
次は添え字を使って、文字列の一部の中身を変えます。 添え字で指定した位置に文字を上書きしたい場合には
添え字で指定した位置に文字を上書きしたい場合には![]() と言う形式で指定します。
と言う形式で指定します。
結果は「stoing」です。
次は「ここからここまで」という指定方法で要素を上書きする方法について説明します。 「a[2..5]」は文字列の2番目から5番目まで要素を
「a[2..5]」は文字列の2番目から5番目まで要素を![]() で置き替えるので、答えは「star」になります。
で置き替えるので、答えは「star」になります。
次は文字列同士をつなげる方法について説明します。
では例をみてみましょう。 文字列同士をつなげて新しい文字列を作成するには「+」を使用します。
文字列同士をつなげて新しい文字列を作成するには「+」を使用します。
結果は「string123」です。
他の方法でも文字列同士をつなげることは出来ますので例をみてみましょう。
 文字列同士をつなげる方法は2つあり、1つ目は
文字列同士をつなげる方法は2つあり、1つ目は![]() 2つ目は
2つ目は![]() を使います。
を使います。
これらを使った場合は元の文字列自体の値が変わります。
次は文字列同士を比較する方法について説明します。
では例をみてみましょう。 文字列同士が一致しているかどうかを調べるには
文字列同士が一致しているかどうかを調べるには![]() を使います。
を使います。
一致していればtrue、一致していなければfalseになります。
次の例をみてみましょう。 文字列同士が一致していないかを調べるには
文字列同士が一致していないかを調べるには![]() を使います。
を使います。
一致していなければtrue、一致していればfalseになります。
次の例は文字列を繰り返す演算子について説明します。 「文字列*繰り返す回数」という構文で文字列を繰り返すことが出来ます。
「文字列*繰り返す回数」という構文で文字列を繰り返すことが出来ます。
この例では![]() と言う文字列を3回繰り返しています。
と言う文字列を3回繰り返しています。
結果は![]() です。
です。
次は文字列の中の文字が何番目にあるのかを調べる方法について説明します。
 指定の文字列の中で検索したい文字が何番目にあるのかを調べ、その位置を数値で返します。
指定の文字列の中で検索したい文字が何番目にあるのかを調べ、その位置を数値で返します。
indexメソッドは前から検索を始めて、rindexメソッドは後ろから検索を始めます。
しかし、何番目にあるのかを数えるのはindexでもrindexでも前からです。
a.index(“n”)は前から検索をするので、結果は4です。0から数えて4番目にあると言う意味です。
a.rindex(“n”)は後ろから検索するので、結果は16です。
ここで注意して欲しいのは後ろから指定文字を検索をするのですが、結果である指定文字の位置の特定は前から数えると言うことです。
では次に進みます。
文字列の中の何番目にあるかでは無くて、ただその文字が存在するかどうかを調べるには![]() を使います。
を使います。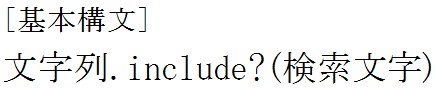 文字列の中に検索文字が存在するかどうかを調べます。
文字列の中に検索文字が存在するかどうかを調べます。
含まれるときはtrue、含まれないときにはfalseを返します。
では例をみてみましょう。 結果は「yes」です。
結果は「yes」です。
次は文字列の一部分を削除するslice!メソッドについて説明します。
では例をみてみましょう。
 結果はbを削除したので「acd」です。
結果はbを削除したので「acd」です。
次の例をみてみましょう。
 結果はb,c,dを削除したので「aefg」です。
結果はb,c,dを削除したので「aefg」です。
次の例をみてみましょう。
 結果はb,c,dを削除したので「aefg」です。
結果はb,c,dを削除したので「aefg」です。
次はユーザーに何かを入力してもらう時に使うgetsメソッドについて説明します。
では例をみてみましょう。 まず初めに「年齢は?」と入力するように促します。
まず初めに「年齢は?」と入力するように促します。
そして、「65」と、入力すると、その入力した結果がageに代入され、結果が出力されます。 このようにユーザーに入力させるためのメソッドがgetsメソッドです。
このようにユーザーに入力させるためのメソッドがgetsメソッドです。
ここで気を付けてほしいことは入力値が入っているage変数には改行も一緒に入っていますので![]() と出力しても、以下のように
と出力しても、以下のように![]() だけが改行されてしまいます。
だけが改行されてしまいます。 そこでこの改行を消す機能がRubyには用意されていますので、次の例を見てみましょう。
そこでこの改行を消す機能がRubyには用意されていますので、次の例を見てみましょう。
 chompメソッドは、文字列の最後の改行文字を取り除いた新たな文字列を作成します。
chompメソッドは、文字列の最後の改行文字を取り除いた新たな文字列を作成します。
この例ではユーザーが入力した文字列の改行を取り除きます。
結果は以下の通り、改行が取り除かれているのが分かります。 その他にchomp!メソッドもありますが、これは元の文字列自体から改行を取り除いたものを作成します。
その他にchomp!メソッドもありますが、これは元の文字列自体から改行を取り除いたものを作成します。 では例をみてみましょう。
では例をみてみましょう。 結果は「abcd」です。
結果は「abcd」です。
次はchompメソッドと同じようなメソッドのchopメソッドやchop!メソッドについて説明します。
chopメソッドは文字列の末尾が改行でも普通の文字でも関係なく、末尾を削除した新しい文字列を作成します。
chop!メソッドはchopメソッドと機能が同じですが、新しい文字列を作成するのではなく、元の文字列自体から末尾の文字を取り除いたものを作成します。 では例をみてみましょう。
では例をみてみましょう。 結果はdが取り除かれているので「abcです」が出力されます。
結果はdが取り除かれているので「abcです」が出力されます。
chopメソッドの例をみてみましょう。 ユーザーに入力してもらう場合はgets.chopと、記述します。
ユーザーに入力してもらう場合はgets.chopと、記述します。
結果は以下の通りです。
次はeach_lineメソッドについて説明します。このメソッドは繰り返し構文の一種ですが、文字列を指定文字で分割して、一行ずつ取り出してくれます。
では例をみてみましょう。
![]() 引数を記述するとその文字列が改行文字になります。
引数を記述するとその文字列が改行文字になります。
引数を省略するとデフォルトでは![]() が改行文字になります。
が改行文字になります。 改行文字を取り除いて文字列を出力したい場合は以下のようにchompを付けます。
改行文字を取り除いて文字列を出力したい場合は以下のようにchompを付けます。 結果は「123」です。
結果は「123」です。
次はeach_byteメソッドについて説明します。
では例をみてみましょう。
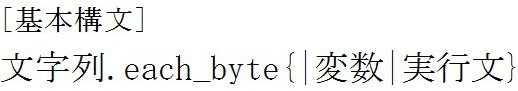 each_byteメソッドは文字列の中の一文字一文字のバイトコードを取り出して、変数に入れて出力するメソッドです。
each_byteメソッドは文字列の中の一文字一文字のバイトコードを取り出して、変数に入れて出力するメソッドです。
結果は「8297」です。
R の文字コードが82で、aの文字コードが97なので、8297が出力されます。
次はeach_charメソッドについて説明します。
では例をみてみましょう。
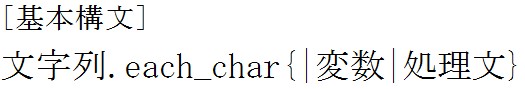 このメソッドは文字列の一文字一文字に対して繰り返し操作を加えるメソッドです。
このメソッドは文字列の一文字一文字に対して繰り返し操作を加えるメソッドです。
結果は「1+2+3+4+」ですが、このように文字と文字の間に何か他の要素を入れたりすることが出来ます。
変数の値を他の文字と結びつけるには![]() と書きます。
と書きます。
次は文字列の中から特定の要素を削除するdeleteメソッドとdelete!メソッドについて説明します。
では例をみてみましょう。
 deleteメソッドは文字列の中から特定の要素を削除した新しい文字列を作成します。
deleteメソッドは文字列の中から特定の要素を削除した新しい文字列を作成します。
delete!メソッドは新しい文字列を作成するのではなく、元の文字列から特定の要素を削除した文字列を作成します。
結果は「いうえお」です。
次の例をみてみましょう。 結果は「いうえお」です。
結果は「いうえお」です。
次は文字列を浮動小数点数(Floatオブジェクト)に変換するto_fメソッドについて説明します。
では例をみてみましょう。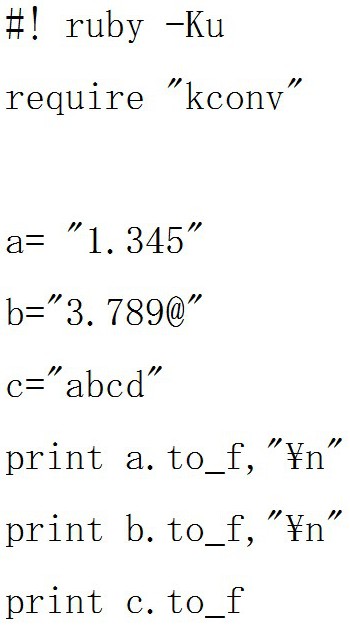 文字列を浮動小数点数に変換しますが、3.789@の中の「@」のように浮動小数点数とは関係ない要素は削除されます。
文字列を浮動小数点数に変換しますが、3.789@の中の「@」のように浮動小数点数とは関係ない要素は削除されます。
![]() のようにすべて浮動小数点数とは関係ない要素の場合は「0.0」が出力されます。
のようにすべて浮動小数点数とは関係ない要素の場合は「0.0」が出力されます。
結果は以下の通りです。
文字列を10進数の整数に変換するto_iメソッドについて説明します。
では例をみてみましょう。
 文字列を10進数の整数に変換しますが、小数点以下は削除されます。
文字列を10進数の整数に変換しますが、小数点以下は削除されます。
3.789@の中の「@」のように整数とは関係ない要素は削除されます。
![]() のようにすべて整数とは関係ない要素の場合は0が出力されます
のようにすべて整数とは関係ない要素の場合は0が出力されます
結果は以下の通りです。
次はreverse!メソッドとreverseメソッドについて説明します。
では例をみてみましょう。
 これは文字列を逆順に並べるメソッドです。
これは文字列を逆順に並べるメソッドです。
reverseメソッドは文字列を逆順に並べた新しい文字列を作成します
reverse!メソッドは元の文字列の順序を逆順にしたものを作成します。
結果は「おえういあ」です
次の例をみてみましょう。 結果は「おえういあ」です。
結果は「おえういあ」です。
次は文字列を他の文字列に変更するreplaceメソッドについて説明します。
では例をみてみましょう。
 このメソッドは文字列を別の文字列に変更します。
このメソッドは文字列を別の文字列に変更します。
この例では「あいうえお」を「かきくけこ」に書き替えます。
結果は「かきくけこ」です。
次は小文字を大文字に変換するupcase!メソッドとupcaseメソッドについて説明します。
では例をみてみましょう。
 upcaseメソッドは小文字を大文字に変換した新しい文字列を作成します。
upcaseメソッドは小文字を大文字に変換した新しい文字列を作成します。
upcase!メソッドは元の文字列を小文字から大文字に変換した文字列を作成します。
結果は「ABCD」です。
次の例を例をみてみましょう。 結果は「ABCD」です。
結果は「ABCD」です。
次は大文字を小文字に変換するdowncase!メソッドとdowncaseメソッドについて説明します。
では例をみてみましょう。
 downcaseメソッドは大文字を小文字に変換した新しい文字列を作成します。
downcaseメソッドは大文字を小文字に変換した新しい文字列を作成します。
downcase!メソッドは新しい文字列を作成するのではなく、元の文字列を大文字を小文字に変換した文字列を出力します。
結果は「abcd」です。
次の例をみてみましょう。 結果は「abcd」です。
結果は「abcd」です。
次は文字列がカラかどうかを調べるempty?メソッドについて説明します。
では例をみてみましょう。
 文字列がカラであるならばtrue,文字列に何か入っていればfalseです。
文字列がカラであるならばtrue,文字列に何か入っていればfalseです。
結果は「カラです」が出力されます。
次は文字列の中の特定の文字の要素数を調べるcountメソッドについて説明します。
では例をみてみましょう。
![]() は文字列の中にaが何個あるかを調べ、
は文字列の中にaが何個あるかを調べ、![]() は文字列の中にabが何個あるかを調べ,
は文字列の中にabが何個あるかを調べ,![]() は文字列の中にaからzまでのアルファベットが何個あるかを調べています。
は文字列の中にaからzまでのアルファベットが何個あるかを調べています。 先頭の小文字を大文字して、残りの文字列は小文字にするcapitalize!メソッドとcapitalizeメソッドについて説明します。
先頭の小文字を大文字して、残りの文字列は小文字にするcapitalize!メソッドとcapitalizeメソッドについて説明します。
では例をみてみましょう。
 capitalizeメソッドは先頭の文字を大文字して、残りの文字列は小文字にする新しい文字列を作成します。
capitalizeメソッドは先頭の文字を大文字して、残りの文字列は小文字にする新しい文字列を作成します。
capitalize!メソッドは新しい文字列を作成するのではなく、元の文字列の先頭の文字を大文字して、残りの文字列は小文字にする文字列を作成します。
結果は「Abcd」です。
次の例をみてみましょう。 結果は「Abcd 」です。
結果は「Abcd 」です。
次は文字列の最初の文字を取り除くchrメソッドについて説明します。
では例をみてみましょう。
 取り除かれた文字列の最初の文字が返されます。
取り除かれた文字列の最初の文字が返されます。
結果は文字列の最初の文字「A」が出力されます。
次は文字列をカラ文字にするclearメソッドについて説明します。
では例をみてみましょう。
 結果は文字列をカラにするので
結果は文字列をカラにするので![]() です。
です。
つまりカラ文字です。