この章では三項演算子について説明します。
if文と似たようなことは以下の三項演算子で行うことが出来ます。
 では例をみてみましょう(スペースの都合上三項演算子を2行で書いています)。
では例をみてみましょう(スペースの都合上三項演算子を2行で書いています)。
 では説明を始めます。
では説明を始めます。 が実行されるのですが、この例の場合はTRUEなので「にゃー」が$animalに代入されます。
が実行されるのですが、この例の場合はTRUEなので「にゃー」が$animalに代入されます。
上の三項演算子の例をif文で書き替えますと次のようになります。

この章では三項演算子について説明します。
if文と似たようなことは以下の三項演算子で行うことが出来ます。
では例をみてみましょう(スペースの都合上三項演算子を2行で書いています)。
では説明を始めます。が実行されるのですが、この例の場合はTRUEなので「にゃー」が$animalに代入されます。
上の三項演算子の例をif文で書き替えますと次のようになります。
この章ではif文の応用で星座の判定プログラムを作ります。
長いプログラムですが、ifが連続しているだけです(クリックすると拡大します)。






 初めに$Monthに入っている値をチェックして、その数字に一致するif文の箇所に入ります。この例ですと$Monthは1なので、以下のif文に入ります。
初めに$Monthに入っている値をチェックして、その数字に一致するif文の箇所に入ります。この例ですと$Monthは1なので、以下のif文に入ります。
 1月ですと、水瓶座と山羊座の2つの星座があるので、これをさらに入れ子のif文で分別して、星座を求めています。
1月ですと、水瓶座と山羊座の2つの星座があるので、これをさらに入れ子のif文で分別して、星座を求めています。
$Dayの値が範囲以外の数値であれば![]() が出力されます。
が出力されます。
また、$Monthの値が12を超えた数値ですと以下の![]() が出力されます。
が出力されます。
この章ではif文を入れ子にする方法について説明します。
if文は入れ子にすることが出来ます。
つまり、if文の中にif文を含めることができるということです。
次のようにif文の中にさらにif文が含まれている構造です。
 $nameは「”手塚”」なので、
$nameは「”手塚”」なので、![]() はTRUEです。
はTRUEです。
TRUEによりさらに入れ子の中の次のif文が実行されます。
 $ageは23で、18を超えていますので
$ageは23で、18を超えていますので
![]() が実行されます。
が実行されます。
このように先頭の条件式がTRUEであるならば、さらに条件を絞りたい場合にifの入れ子を使用します。
つまり、この例では「手塚さんであることは確認しましたが、さらに年齢を確かめたいので質問しますね。
手塚さんは18歳を超えていますか?」ということです。
この章でもif文について説明します。
if文の基本構文2の応用で、条件式が複数ある場合、つまり細かい条件を設定したい場合には![]() を使います。
を使います。
基本構文1,基本構文2は「条件に合うか合わないか」を判断するのみのプログラムでしたが、![]() は条件1がFALSEならば条件式2、条件式2もFALSEならば条件式3, 条件式3もFALSEならばelseの実行文というような条件の複数指定です。
は条件1がFALSEならば条件式2、条件式2もFALSEならば条件式3, 条件式3もFALSEならばelseの実行文というような条件の複数指定です。
具体的には、以下のような書式になります。

 上の構文ではelsif を2つしか書いていませんが、いくつでも指定することができます。
上の構文ではelsif を2つしか書いていませんが、いくつでも指定することができます。
では例をみてみましょう。
 $aと$bは同じ数値なので、
$aと$bは同じ数値なので、![]() が出力されます。
が出力されます。
この章でもif文について説明します。
ifの基本構文1では条件式がFALSEの場合には、if文は何の処理も行われませんでした。
そこで、条件式がFALSEの場合にも、何かしらの処理がしたい場合に使用するのが![]() です。
です。
 では例をみてみましょう。
では例をみてみましょう。
 条件式は$numが70より小さいならばと言う意味なのですが、この例では$numは70より大きいのでFALSEです。
条件式は$numが70より小さいならばと言う意味なのですが、この例では$numは70より大きいのでFALSEです。
FALSEなので条件式がFALSEのときに実行される文である![]() が実行されます。
が実行されます。
この章ではif文について説明します。
if文はどのような時に使われるのかを日常生活の中の場面で説明します。
例えば、もし、今日財布にお金が10000円あったらフランス料理にして、20000円あったら中華料理にするなどの選択を繰り返して人は生きていますが、プログラムでもこのような表現ができるのです。
このように条件によって表現を変えることを条件分岐と言います。
 例のif文を見ていただければわかるようにprint文が少し右にずれていますが、これをインデントと言います。
例のif文を見ていただければわかるようにprint文が少し右にずれていますが、これをインデントと言います。
プログラムは誰が読んでも解りやすいように、空白を入れたり、文字を下げたりすることが必要です。
「条件式」には次の表にあるような関係演算子を使って![]() とか
とか![]() などを
などを![]() を使って表現します。
を使って表現します。
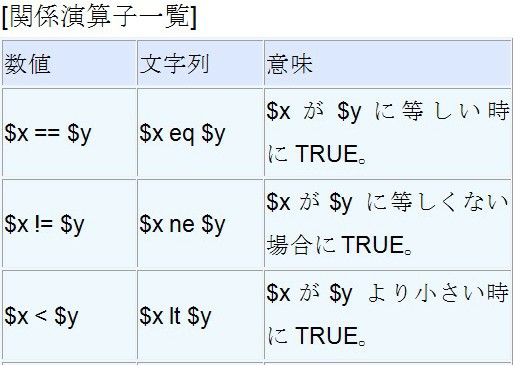

 条件式は条件を満たしていればTRUEを返し、条件を満たしていないならばFALSEを返します。
条件式は条件を満たしていればTRUEを返し、条件を満たしていないならばFALSEを返します。
そして、TRUEの時にif文が実行されます。
では何がTRUEで、何がFALSEであるかを見てみましょう。
 条件式の中では関係演算子の中の
条件式の中では関係演算子の中の![]() を使用していますが、常識的に考えて125は123より大きいですので、条件を満たしていると考えるのです。
を使用していますが、常識的に考えて125は123より大きいですので、条件を満たしていると考えるのです。
これがTRUEです。
TRUEですので、![]() が実行されます。
が実行されます。
もっと正確に言うと、条件式は条件を満たしていればTRUEになりif文が実行され、条件を満たしていないならばFALSEになりif文は実行されません。
関係演算子を使用する場合には比較対象が数値なのか文字列なのかによって使用する記号は違いますので、表で確認してください。
では次の例を見てみましょう。
「$animal」の中には犬が入っていますので、条件式はTRUEです。
 これは文字列として等しいかどうかを比較しているので関係演算子はeqです。
これは文字列として等しいかどうかを比較しているので関係演算子はeqです。
以下のように数値として等しいかどうかを比較したいのであれば![]() を使用します。
を使用します。
 次はfalseの例です
次はfalseの例です
 この例の結果は何も表示されません。
この例の結果は何も表示されません。
なぜかと言いますと![]() の部分が条件を満たしていないからです。
の部分が条件を満たしていないからです。
つまりFALSEになり,ブロックの中が実行されません。
次の例を見てみましょう。
 上の例は関係演算子を使用しないif文です。関係演算子を使用しない場合のTRUEとFALSEの条件は以下のようになります。
上の例は関係演算子を使用しないif文です。関係演算子を使用しない場合のTRUEとFALSEの条件は以下のようになります。
 下の例はすべてFALSEですので、if文は実行されません。
下の例はすべてFALSEですので、if文は実行されません。
この章ではforeach文について説明します。
今までは次のように1つずつ配列からデータを取り出していましが、foreachを使うとすべての配列の要素を簡単に取り出すことができます。

では例をみてみましょう。

 foreachは、リストや配列の一番前から順番に$an変数にセットされて、ブロックの中身である文を実行します。
foreachは、リストや配列の一番前から順番に$an変数にセットされて、ブロックの中身である文を実行します。
配列やリストの要素がすべてを変数に出力されたら繰り返しが終了します。





 では例をみてみましょう。
では例をみてみましょう。
 最初の例では配列の要素をただ単に出力しただけですが、この例の場合には$anに
最初の例では配列の要素をただ単に出力しただけですが、この例の場合には$anに![]() を連結演算子で付けて出力しています。
を連結演算子で付けて出力しています。
![]() は
は![]() と同じ意味です。
と同じ意味です。
このようにforeach内で配列の要素に変更を加えると元の配列まで影響を受けます。
試しに![]() と出力すると分かりますが
と出力すると分かりますが![]() のように元の配列の要素まで変わっているのが分かります。
のように元の配列の要素まで変わっているのが分かります。
次の例をみてみましょう。
 結果は12です。
結果は12です。
プロセスは前の例と同じですが、foreachの中の変数である$goukeiを外で出力しています。
このようにブロックの中の変数を外で出力することが出来ます。
注意してほしいのが、この例の![]() のようにforeach と
のようにforeach と![]() の間の変数はブロック外で出力することができません。
の間の変数はブロック外で出力することができません。
この例の場合は$hですが、この変数を制御変数と言います。
この制御変数はブロックの中でだけ有効な変数ですので、ブロックの外で同じ名前の変数を作成しても問題ありません。
では以下の例で確認しましょう。
以下の例の1行目の$anとforeachの$anはお互いに影響を受けません。全く違う変数になります。
 次は制御変数を使わないで配列の要素を出力する方法について説明します。
次は制御変数を使わないで配列の要素を出力する方法について説明します。
構文は以下の通りです。
 では次の例を上の構文を使って書き換えてみます。
では次の例を上の構文を使って書き換えてみます。
 以下のように書き替えることも出来ます。
以下のように書き替えることも出来ます。
 制御変数を省略した場合は
制御変数を省略した場合は![]() が制御変数として使われます。
が制御変数として使われます。
![]() はデフォルト変数と呼ばれています。
はデフォルト変数と呼ばれています。
制御変数なので本当は以下の箇所に![]() が隠れていますが、これは省略できます。
が隠れていますが、これは省略できます。

次はmap関数について説明します。
foreachに似た関数にmap関数が有ります。
この関数でもforeachと同じことが出来ます。
 では例をみてみましょう。
では例をみてみましょう。
 map関数は、リストの要素を先頭から順番にブロックの中に代入され、何らかの操作を行った後、その結果をリスト、配列として返してくれます。
map関数は、リストの要素を先頭から順番にブロックの中に代入され、何らかの操作を行った後、その結果をリスト、配列として返してくれます。
この例の場合にはmap関数のブロック内のデフォルト変数に順番に配列の要素が代入していきます。
上の例は以下の例と同じ意味です。
 次の例をみてみましょう。
次の例をみてみましょう。
 配列の各要素が
配列の各要素が![]() に代入され、その変数と文字列である
に代入され、その変数と文字列である![]() とが文字列連結演算子で連結され、その結果が配列として@gtに代入されます。
とが文字列連結演算子で連結され、その結果が配列として@gtに代入されます。
結果は以下の通りです。![]() 次の例をみてみましょう。
次の例をみてみましょう。
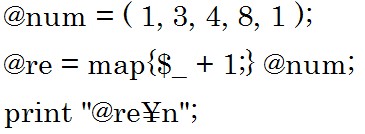 配列の要素がデフォルト変数に代入され、それに1が足されて、その結果が配列として@reに代入されています。
配列の要素がデフォルト変数に代入され、それに1が足されて、その結果が配列として@reに代入されています。
結果は「2 4 5 9 2」です。
次の例をみてみましょう。
以下の形式を添え字を使って書き替えます。
 先ほどの例を添え字を使って書き替えた例が以下です。
先ほどの例を添え字を使って書き替えた例が以下です。
 この例の場合は配列を直接指定する代わりに
この例の場合は配列を直接指定する代わりに![]() を使っています。
を使っています。
「$#animal」は末尾の添え字の番号を意味します。
 例えば以下の配列の末尾の添え字番号を求めるには$#animalと書きます
例えば以下の配列の末尾の添え字番号を求めるには$#animalと書きます
print $#animal;と書けば4が出力されます。
![]() 要素がたくさんある場合は最後の添え字が何番であるかわからなくなりますので、この方法は便利です。
要素がたくさんある場合は最後の添え字が何番であるかわからなくなりますので、この方法は便利です。
では例の説明に戻りますが、![]() の中の$anにはリストの0から4の数字が順番に入りますので、結果は
の中の$anにはリストの0から4の数字が順番に入りますので、結果は![]() です。
です。
補足ですが、![]() の他の使い方について説明します。
の他の使い方について説明します。
 この例のように$#animalを添え字に使うことで配列の末尾の要素に新しいデータを入れることが出来ます。
この例のように$#animalを添え字に使うことで配列の末尾の要素に新しいデータを入れることが出来ます。
つまり、ネズミをネッシーで上書きしています。
結果は![]() です。
です。
では次の例も補足ですが、$#animalと同じ意味を表わす添え字について説明します。
 $animal[-1]のように添え字に「-1」を入力することでも配列の末尾の要素にデータを入れることが出来ます。
$animal[-1]のように添え字に「-1」を入力することでも配列の末尾の要素にデータを入れることが出来ます。
つまり、$#animalと同じです。
後ろから2番目の要素に何かデータを入れたい場合は以下のように添え字に「-2」を入れてください。
つまり添え字をマイナスで書くことで配列の要素に対して後ろからアプローチできます。
この章では文字列に関する関数について説明します。
先ほど配列に関する関数を説明しましたが、今度は文字列を操作する関数について説明します。 substr関数は指定した文字列の中の一部分を取得したり、文字列の一部を他の文字列に置換します。
substr関数は指定した文字列の中の一部分を取得したり、文字列の一部を他の文字列に置換します。
第1引数は対象となる文字列を指定し、第2引数は文字列の中の開始位置を指定し、第3引数は切り出す文字の長さです。
第3引数を省略した場合は文字列の末尾までを取り出します。
第4引数を指定すると1番目から3番目の引数によって指定した文字列を第4引数の文字列で置き換えます。
では例をみてみましょう。 この例では第3,第 4引数を省略しているので、第2引数で指定した位置から、最後までを取得して$n1に代入しています。
この例では第3,第 4引数を省略しているので、第2引数で指定した位置から、最後までを取得して$n1に代入しています。
位置の指定方法で気を付けることは先頭の文字の位置は0であり、1から数えるのではないので、注意してください。
$moji1の文字列は一部をsubstrで取り出されても、$moji1自体は変化しません。
つまり、最後に![]() で出力しても
で出力しても![]() が出力されます。
が出力されます。

 次の例をみてみましょう。
次の例をみてみましょう。
 第 2引数にマイナスの値を入れた場合には以下の図のように末尾から数えます。
第 2引数にマイナスの値を入れた場合には以下の図のように末尾から数えます。
マイナスの値を入れた位置から末尾までを取得して$n2に代入しています。

次の例をみてみましょう。
 Americaの先頭から2番目の文字から2つを取得します。
Americaの先頭から2番目の文字から2つを取得します。
第2引数が2なので2個切り出しています。
結果は「me」です。
次の例をみてみましょう。
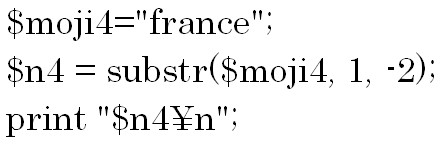 franceの先頭から2番目の文字から、末尾から2番目の文字までの間の文字列を取得します。
franceの先頭から2番目の文字から、末尾から2番目の文字までの間の文字列を取得します。
このように第3引数にマイナスを指定すると第2引数で指定した位置から第3引数で指定した位置までの間の文字列を取り出すことが出来ます。
結果は「ran」です。
次の例をみてみましょう。 4番目の引数には置き換える文字列を指定します。
4番目の引数には置き換える文字列を指定します。
置き換えの文字列は2番目と3番目の引数によって指定した文字列です。
1番目の引数は文字列が代入されている変数でなければいけません。
それは置きかえられた新しい文字列が入れられるようにするためです。
これは元の文字列の内容が書き替わるので注意してください。
結果は以下の通りです。
「hawai is fun」
次はrand関数について説明します。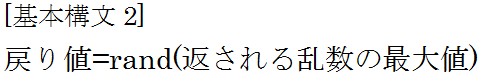 「返される乱数の最大値」を入力すると0から指定した数値未満までの乱数を返します。
「返される乱数の最大値」を入力すると0から指定した数値未満までの乱数を返します。
引数を省略すると、0から1までの値を返します。
また、返される数値には小数点が含まれます。
では例をみてみましょう。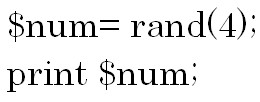 乱数なのでどの数値が出力されるのかはそのたびに変わります。
乱数なのでどの数値が出力されるのかはそのたびに変わります。
この例の場合には引数に4を指定したので、4までの数値が更新するごとに変わります。
例えば小数点を含む値なので![]() などと出力されます。
などと出力されます。
この例は
「print rand(4);」と書いても同じ意味になります。
次の例をみてみましょう。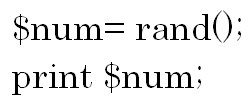 引数を省略した場合には0から1までの値を返しますので、例えば
引数を省略した場合には0から1までの値を返しますので、例えば![]() などと出力されます。
などと出力されます。
次の例をみてみましょう。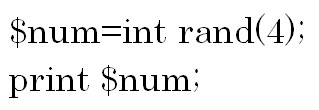 小数点を含む数値の整数の部分だけを取り出すにはrand関数の前にintを付けます。
小数点を含む数値の整数の部分だけを取り出すにはrand関数の前にintを付けます。
例えば![]() という小数点ではなく2と整数が出力されます。
という小数点ではなく2と整数が出力されます。
rand関数の前あるintは int関数と言いまして小数点以下を無視して、整数部分だけを返します。
では以下のint関数についての例を見てみましょう。
以下の例は変数に入っている小数点以下を切り捨てるので、結果は0です。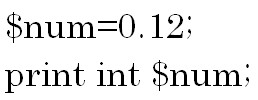 ではrand関数を使っておみくじを作ってみましょう。
ではrand関数を使っておみくじを作ってみましょう。 rand関数を使うと更新ボタンを押すごとに乱数値が変わるので、占いを作ることが出来ます。
rand関数を使うと更新ボタンを押すごとに乱数値が変わるので、占いを作ることが出来ます。
この例ではrand関数の戻り値を配列の添え字にしています。
この例の場合にはint関数は付けても付けなくてもどちらでも結構です。
なぜなら、配列の添え字は整数部分しか入れられないので、自動で小数点以下を切り捨ててくれるからです。
次にucfirst関数について説明します。 ucfirst関数は対象の文字列の先頭の文字を大文字に変換した文字列を返します。
ucfirst関数は対象の文字列の先頭の文字を大文字に変換した文字列を返します。 結果は「America」になります。
結果は「America」になります。
以下のように書いても同じ意味になります。 すべての文字を大文字に変換したい場合はuc関数を使います。
すべての文字を大文字に変換したい場合はuc関数を使います。

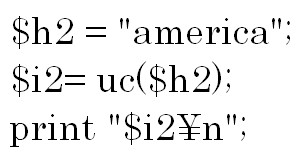 結果は「AMERICA」になります。
結果は「AMERICA」になります。
対象の文字列の先頭を小文字に変換したい場合はlcfirst関数を使います。

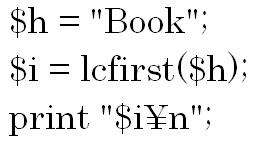 結果は「book」になります。
結果は「book」になります。
対象となる文字列を全て小文字に変換するにはlc関数を使います。

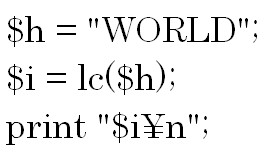 結果は「world」になります。
結果は「world」になります。
次はindex関数について説明します。
 index関数は対象となる文字列の中に第2引数で指定した文字列が含まれているかどうかを検索し、含まれている場合は最初に見つかった位置を数値で返します。
index関数は対象となる文字列の中に第2引数で指定した文字列が含まれているかどうかを検索し、含まれている場合は最初に見つかった位置を数値で返します。
見つからなかった場合は「-1」を返します。
第 3引数の![]() を省略すると0を指定したとみなされます。
を省略すると0を指定したとみなされます。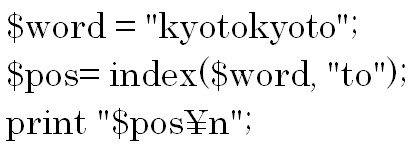 第 3引数を省略しているので検索開始位置は0になります。
第 3引数を省略しているので検索開始位置は0になります。
この例ではtoは前から3つ目の所にあるので3が返されます。
toが2つありますが、最初に見つかった位置を返します。
以下の例のように第3引数に例えば5を入れるとkyotokyotoのなかの5番目の位置から右に検索されるので結果は8になります。
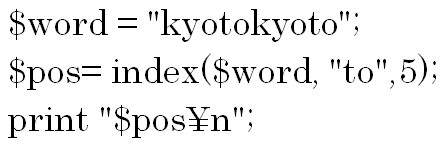
 rindex関数は対象となる文字列の中に第2引数で指定した文字列が含まれているかどうかを検索し、含まれている場合は最後に見つかった位置を数値で返します。
rindex関数は対象となる文字列の中に第2引数で指定した文字列が含まれているかどうかを検索し、含まれている場合は最後に見つかった位置を数値で返します。
第3引数を省略した場合は最後の文字を指定したとみなされます。検索する文字が見つからない場合は「-1」を返します。
では例をみてみましょう。
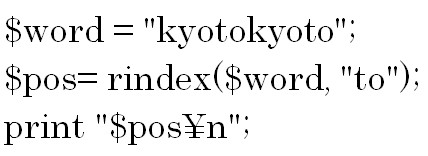 toが2つありますが、rindex関数は検索の結果、最後に見つかった位置を数値で返しますので結果は8になります。
toが2つありますが、rindex関数は検索の結果、最後に見つかった位置を数値で返しますので結果は8になります。
次の例をみてみましょう。
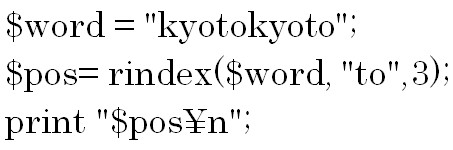 この例の場合は第3引数に3を指定しているので、対象となる文字列であるkyotokyotoの中の前から3番目の文字以内でtoを検索します。
この例の場合は第3引数に3を指定しているので、対象となる文字列であるkyotokyotoの中の前から3番目の文字以内でtoを検索します。
結果は「3」になります。
 次は文字列の長さを測る関数lengthについて説明します。
次は文字列の長さを測る関数lengthについて説明します。
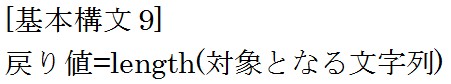 では例をみてみましょう。
では例をみてみましょう。
 結果は以下の通りです。
結果は以下の通りです。
長さは5
長さは9
UTF-8は英数字は1バイトで数えて、日本語は3バイトで数えるようになっています。
英数字の場合はバイト数と文字数は同じになります。
文字コードによりバイト数は違うので注意してください。
この章では配列の関数について説明します。
関数は入力したデータに基づいて決められた処理を行い、戻り値という結果を返す機能を持っています。
このデータは引数と呼ばれています。 引数1は第1引数、引数2は第2引数と言います。
引数1は第1引数、引数2は第2引数と言います。
ここでは第2引数までしか書いていませんが引数3、引数4と続きます。
引数の数は関数によって違います。
では関数についてさらに詳しく説明します。
「Perlの基礎を知ろう」の章では関数については以下の通り説明しました。
Perlの関数の仕組みはエクセルの関数の仕組みと意味は同じです。エクセルをご存知の方はわかると思いますが、例えばエクセル関数にSUMと言う関数が有りますが、この関数は指定した範囲のデータに基づいて足し算を行う関数です。
例えば指定した範囲のデータが3,5,7であるならば結果は15です。SUMには初めから指定した範囲の足し算を行うと言う仕組みが備わっています。
つまり、エクセルの内部機構でSUMの機能は指定した範囲の足し算を行うと言うプログラムがされていると言うことです。
これが関数の意味です。
Perlには初めからこのように機能が定義されている関数が多数ありますので、配列に関係する関数を取り上げたいと思います。
printは出力する関数でしたが、配列の関数は配列のデータの順番を変えたりする便利な関数が多数ありますので、次で紹介します。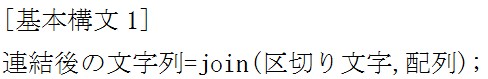 join関数は配列を指定した区切り文字で連結して、その結果を戻り値として返します。
join関数は配列を指定した区切り文字で連結して、その結果を戻り値として返します。 結果は以下の通りです。
結果は以下の通りです。
「猫と犬とライオンと象とネズミ」
色々区切り文字を入れて試してみてください。 shift関数は配列の先頭の要素を切り取って、その切り取った要素を返します。
shift関数は配列の先頭の要素を切り取って、その切り取った要素を返します。 $rには取り除いた要素である猫が代入されています。取り除かれた後の配列の要素は改めて添え字が振り直されますので、添え字の先頭は犬になります。
$rには取り除いた要素である猫が代入されています。取り除かれた後の配列の要素は改めて添え字が振り直されますので、添え字の先頭は犬になります。
 unshift関数は配列の先頭に要素を追加します。
unshift関数は配列の先頭に要素を追加します。 $rには要素追加後の要素数が入りますので6が代入され、@animalは蛙を先頭に追加したので
$rには要素追加後の要素数が入りますので6が代入され、@animalは蛙を先頭に追加したので![]() となります。
となります。 pop関数は配列の末尾のデータを取り除きます。
pop関数は配列の末尾のデータを取り除きます。 $pには取り除いた要素であるネズミが代入され、@animalはネズミが取り除かれていますので
$pには取り除いた要素であるネズミが代入され、@animalはネズミが取り除かれていますので![]() となります。
となります。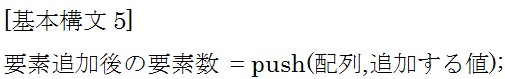 push関数は配列の末尾にデータを追加します。
push関数は配列の末尾にデータを追加します。 $tには要素追加後の要素数が入りますので6が代入され、@animalは蛇を末尾に追加したので
$tには要素追加後の要素数が入りますので6が代入され、@animalは蛇を末尾に追加したので![]() となります。
となります。
 sort関数は氏名やID番号などのデータをアルファベット順や番号順などで並び替える時に使います。
sort関数は氏名やID番号などのデータをアルファベット順や番号順などで並び替える時に使います。
次の通り、sortの基本構文は複数ありますが、順番に説明していきます。

 結果は以下の通りです。
結果は以下の通りです。
「E a b c d f」
標準の文字列比較の順番で文字が昇順に並び替えられます。
順序は
〇abc順
〇大文字は小文字より前
〇数値はアルファベットより前という法則で決まります。
![]() 文字を昇順で比較したい場合は上の構文を使用します。
文字を昇順で比較したい場合は上の構文を使用します。
cmpは文字コードで比較するときに使う演算子です。 結果は以下の通りです。
結果は以下の通りです。
「a b c d e f」
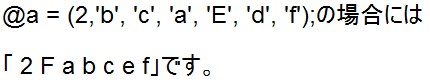 数値が1番前に来ているのが分かります。
数値が1番前に来ているのが分かります。
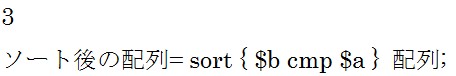 文字コードの降順で比較したい場合は上の構文を使用します。
文字コードの降順で比較したい場合は上の構文を使用します。
「sort { $a cmp $b } 配列;」との違いは$aと$bの位置です。
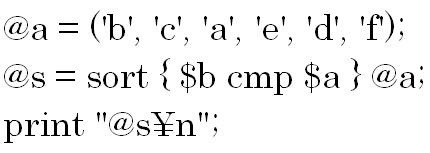 結果は以下の通りです。
結果は以下の通りです。
「f e d c b a」
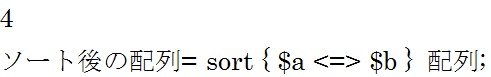 数値を昇順、つまり123順で比較したい場合は上の構文を使用します。
数値を昇順、つまり123順で比較したい場合は上の構文を使用します。
cmpは文字コードで比較するときに使う演算子でしたが、![]() は数値で比較するときに使う演算子です。
は数値で比較するときに使う演算子です。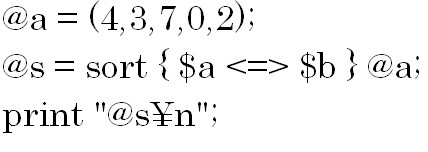 結果は「0 2 3 4 7」です。
結果は「0 2 3 4 7」です。
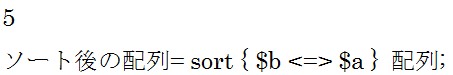 数値を降順で比較したい場合は上の構文を使用します。
数値を降順で比較したい場合は上の構文を使用します。
sort { $a <=> $b } 配列;との違いは$aと$bの位置です。
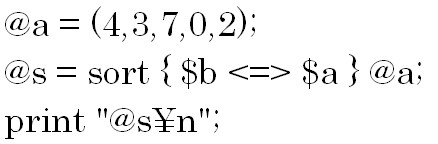 結果は「7 4 3 2 0」です。
結果は「7 4 3 2 0」です。
 reverse関数は引数に指定した配列に含まれる要素を逆に並べた配列を返します。
reverse関数は引数に指定した配列に含まれる要素を逆に並べた配列を返します。
 結果は以下の通りです。
結果は以下の通りです。
2 0 7 3 4
f d E a c b
 しかし、splice関数を使用すれば配列の先頭もしくは末尾以外から要素を取り出すことが可能になります。
しかし、splice関数を使用すれば配列の先頭もしくは末尾以外から要素を取り出すことが可能になります。
splice関数には幾つかの構文があります。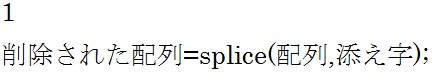 添え字で指定した箇所から末尾までを削除した配列を返します。
添え字で指定した箇所から末尾までを削除した配列を返します。
 この例ではsplice関数の第2引数が1なので、配列の犬から末尾までの要素が削除対象になります。
この例ではsplice関数の第2引数が1なので、配列の犬から末尾までの要素が削除対象になります。
@seには配列の中の削除した要素が代入されていますので、
結果は![]() です。
です。
@animalには削除後の要素である猫が入っています。
 配列の先頭から末尾までを削除したリストを返します。
配列の先頭から末尾までを削除したリストを返します。
 この例ではsplice関数の第2引数を指定していないので、配列のすべての要素が削除対象になります。
この例ではsplice関数の第2引数を指定していないので、配列のすべての要素が削除対象になります。
@seには配列の中の削除した要素が代入されていますので、
結果は![]() です。
です。
@animalにはすべてを削除したので何も残っていません。
 添え字で指定した箇所から指定した数だけ削除したリストを返します。
添え字で指定した箇所から指定した数だけ削除したリストを返します。
 この例ではsplice関数の第2引数に1を指定しているので犬から2個削除した配列を返します。
この例ではsplice関数の第2引数に1を指定しているので犬から2個削除した配列を返します。
@seには配列の中の削除した要素が代入されていますので、結果は![]() です。
です。
@animalには削除後の要素である![]() が入っています。
が入っています。
 添え字で指定した箇所から指定した数だけ削除して、その削除した箇所に新たなリストを加えます。
添え字で指定した箇所から指定した数だけ削除して、その削除した箇所に新たなリストを加えます。
そしてその削除した要素を返します。
 この例ではsplice関数の第2引数に1を指定しているので犬から2個削除してから、その削除した箇所に@animal2の要素を加えます。
この例ではsplice関数の第2引数に1を指定しているので犬から2個削除してから、その削除した箇所に@animal2の要素を加えます。
@seには配列の中の削除した要素が代入されていますので、結果は「犬 ライオン」です。
@animalには削除した箇所に龍、ネッシーを加えているので、![]() になります。
になります。
この章では配列について説明します。
普通の$bookのような変数は1つしかデータを入れることができません。
つまり、変数は他のデータを入れようとするとデータが上書きされてしまいます。
それに対して配列は複数のデータをまとめて入れることができます。
複数のデータを扱う場合、変数では以下のように別々の変数名でそれぞれのデータを入れなければいけません。 配列を使うと以下のように1つの配列名@animalで複数のデータを入れることができるのです。
配列を使うと以下のように1つの配列名@animalで複数のデータを入れることができるのです。![]() @animalの中には
@animalの中には![]() がお互い関係性を持って存在していると言えます。
がお互い関係性を持って存在していると言えます。
この例のように同じ目的で使用するデータは1つにまとめてしまい、1つの配列で複数のデータを管理できると便利です。
このような時に配列を使用します。 配列を扱う時には配列名の前にアットマーク@ を付けます。
配列を扱う時には配列名の前にアットマーク@ を付けます。
そして右辺はカッコの中をカンマで区切って要素を入力していきます。
例えば![]() のようにデータをカッコで囲んで、カンマ区切りで複数のデータを作っていきますが、このようなデータをリストと言います。そのリストを左辺の配列名に入れます。例えば以下のように作成します。
のようにデータをカッコで囲んで、カンマ区切りで複数のデータを作っていきますが、このようなデータをリストと言います。そのリストを左辺の配列名に入れます。例えば以下のように作成します。![]() この配列に入っているデータは「添え字」といわれるもので管理します。
この配列に入っているデータは「添え字」といわれるもので管理します。
添え字とはデータが保管してある場所の概念で、0から番号が付けられていきます。
例えばコインロッカーには番号が付いていますが、番号が付いているからこそ、どこに自分の荷物があるのか分かりますが、これと同じで配列のデータは添え字で管理します。 この$animalの右についてる[0]や[1]が添え字です。
この$animalの右についてる[0]や[1]が添え字です。
リストの中の個別のデータを指し示すためには@animal[0]ではなく$animal[0]と書きます。
つまり、先頭の記号は@ ではなく$です。
例えば「print $animal[0];」で出力すると「猫」が出力できます。 先ほども説明しましたが、添え字は0から順番に番号が付けられていきます。
先ほども説明しましたが、添え字は0から順番に番号が付けられていきます。
配列の一番先頭のデータに対応する添え字は1ではなく0です。
では![]() を例に取って配列について、さらに詳しく説明します。
を例に取って配列について、さらに詳しく説明します。 上の配列文は以下のように書く事も出来ます。
上の配列文は以下のように書く事も出来ます。 qwはデータ間をスペースやタブなどの空白文字で区切ったリストを作成する演算子です。
qwはデータ間をスペースやタブなどの空白文字で区切ったリストを作成する演算子です。
qw演算子の中の文字列はシングルクォートで囲まれたものとみなされるので、文字列を囲う必要はありません。



@animal1と@animal2のリストから、新しい配列@animal3
を作成しています。
結果は![]() です。
です。 以下の例のように新しい配列@animal3を作成した後に@animal1や@animal2の内容が変化しても@animal3には影響しません。
以下の例のように新しい配列@animal3を作成した後に@animal1や@animal2の内容が変化しても@animal3には影響しません。
以下の例のように@animal3を作成した後に@animal2に龍を加えても、@animal3には影響がありません。
結果は変わらず「猫 犬 ライオン 象 ネズミ コアラ ネッシー」です。
 例の中のコメントのしてある箇所
例の中のコメントのしてある箇所![]() は
は![]() と同じことを意味しています。
と同じことを意味しています。
リストの中にある「..」を範囲演算子と言います。
例えば(1..100)は1から100までを意味しています。
実際、1から100までをリストに書いていくことは効率が良くないので、このような場面で範囲演算子を使用します。


 添え字は0から順番に番号が付けられていきます。
添え字は0から順番に番号が付けられていきます。
2つの配列の対応関係を図にしたので参考にしてみてください。 もっと詳しく対応関係を説明しますと以下のようになります。
もっと詳しく対応関係を説明しますと以下のようになります。 以下の構文でも配列の要素にデータを入れることが出来ます。
以下の構文でも配列の要素にデータを入れることが出来ます。 今までは以下のように1個1個配列に値を入れていましたが、上の配列の基本構文でも配列にデータを入れることが出来ます。
今までは以下のように1個1個配列に値を入れていましたが、上の配列の基本構文でも配列にデータを入れることが出来ます。 先ほどの構文では以下のようにデータを入れていきます。
先ほどの構文では以下のようにデータを入れていきます。 これはリストを使ったデータの代入の仕方です。
これはリストを使ったデータの代入の仕方です。
この構文であれば右辺のリストの要素を一気に左辺の変数に代入することが出来ます。
右辺のリストの要素数のほうが、左の変数より多い場合は、余った値は捨てられます。
では例をみてみましょう。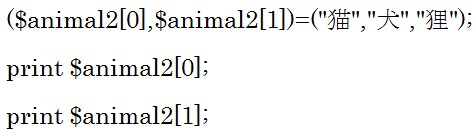 結果は「猫犬」です。
結果は「猫犬」です。
この例の場合は余った狸は捨てられます。
逆に右辺のリストの要素数のほうが、左の変数より少ない場合は余った変数には未定義値であるundefが代入されます。
undefとは変数などが未定義な状態を言います。
undefは何も入っていないのでprintで出力しても画面には現れません。 基本構文は以下の通りです。
基本構文は以下の通りです。![]() では例をみてみましょう。
では例をみてみましょう。 この例では猫が$aに,犬が$bに,ライオンが$cにそれぞれ入ります。
この例では猫が$aに,犬が$bに,ライオンが$cにそれぞれ入ります。
結果は「猫,犬,ライオン」です。
この例はリストを使った以下の方法と同じ意味です。


 配列のデータを変更するには
配列のデータを変更するには![]() や
や![]() のように新たなデータを代入するだけです。
のように新たなデータを代入するだけです。
これで古い要素である猫、犬が上書きされて新しいデータであるキリン、パンダに上書きされます。 配列の要素を出力するには以下の構文で書きます。
配列の要素を出力するには以下の構文で書きます。 では例をみてみましょう。
では例をみてみましょう。
以下の通り、添え字に相当するデータを取り出すことが出来ます。

次は配列全体の要素を出力する方法について説明します。 今までは個別に
今までは個別に
print $animal[1];
print $animal[2];
と出力していましたが、配列の要素を一気にすべてを出力させたい場合には以下のように記述します。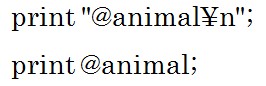 この2種類の出力方法の差は何かといいますと配列をダブルクォートで囲んでいるか、囲んでいないかの差です。
この2種類の出力方法の差は何かといいますと配列をダブルクォートで囲んでいるか、囲んでいないかの差です。
結果は以下のようになります。 ダブルクォートで囲んだ方はデータ間がスペースで区切られます。
ダブルクォートで囲んだ方はデータ間がスペースで区切られます。
ダブルクォートで囲まないとデータ間にスペースが生まれないので、連なって出力されます。 例えば下の配列を初期化したい場合、つまり要素を消したい場合は以下のようにカラのリストを代入します。
例えば下の配列を初期化したい場合、つまり要素を消したい場合は以下のようにカラのリストを代入します。
空にしますとそれ以降は出力することはできません。

{kind=link}