この章では文字列に関する関数について説明します。
配列の関数に続いて今度は文字列に関する関数について説明します。 str_replace関数は元の文字列に関して、置換対象の文字列を置換後の文字列で置き換えます。
str_replace関数は元の文字列に関して、置換対象の文字列を置換後の文字列で置き換えます。
では例をみてみましょう。 元の文字列のカレーを牛丼に置換しています。
元の文字列のカレーを牛丼に置換しています。
結果は![]() です。
です。
今度は元の文字列に配列を使った例を説明します。 配列の中のaをzに置換しています。
配列の中のaをzに置換しています。
結果は以下の通りです。
z
b
c
 mb_substr関数は文字列の一部分を取り出す関数です。
mb_substr関数は文字列の一部分を取り出す関数です。
では例をみてみましょう。
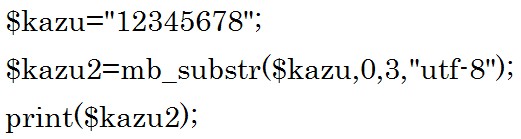 「取り出し開始位置」は前から
「取り出し開始位置」は前から![]() と数えますので、1番前から3個取り出して$kazu2に代入しています。
と数えますので、1番前から3個取り出して$kazu2に代入しています。
結果は 「123」 です。
次の例をみてみましょう。 取り出す文字数を省略すると取り出し開始位置からすべての文字列を取り出します。
取り出す文字数を省略すると取り出し開始位置からすべての文字列を取り出します。
取り出す文字数、文字コードは省略できます。
結果は 「5678」 です。
 str_repeat関数は文字列を指定した回数だけ繰り返す関数です。
str_repeat関数は文字列を指定した回数だけ繰り返す関数です。
では例をみてみましょう。 繰り返す文字列にaを, 繰り返す回数に5を指定しているので、結果は
繰り返す文字列にaを, 繰り返す回数に5を指定しているので、結果は![]() になります。
になります。
 explode関数は対象の文字列を区切り文字で区切った文字列を配列として返します。
explode関数は対象の文字列を区切り文字で区切った文字列を配列として返します。
では例をみてみましょう。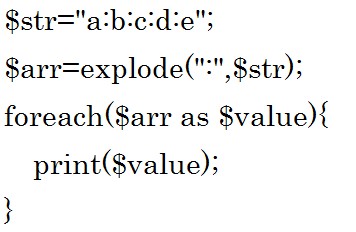 対象文字列$strを
対象文字列$strを![]() で分割したものを配列$arrに入れています。
で分割したものを配列$arrに入れています。
配列なのでforeachで取り出すことが出来ます。
区切り文字は文字列であれば![]() でも
でも![]() でも何でも使うことが出来ます。
でも何でも使うことが出来ます。
結果は「abcde」です。
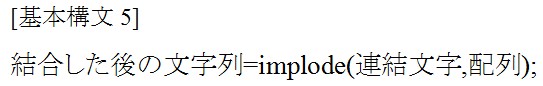 implode関数は配列要素を区切り文字列により連結する関数です。
implode関数は配列要素を区切り文字列により連結する関数です。
 各配列の要素を
各配列の要素を![]() でつなげているので、結果は
でつなげているので、結果は![]() です。
です。
 strlen関数は文字列の長さを測る関数です。
strlen関数は文字列の長さを測る関数です。
長さとはバイト数のことです。
半角英数字は1文字1バイトとして数えています。
おおよそ日本語のようなマルチバイト文字は1文字2バイトですが、文字コードがUTF-8では概ね3バイトで表されます。
つまり、バイト数は、文字コードに依存するので複雑です。
そのような理由から、日本語の文字数を数えたい場合は次に説明します![]() を使いましょう。
を使いましょう。
 結果は以下の通りです。
結果は以下の通りです。
21バイト
13バイト
 mb_strlen関数は日本語などのマルチバイト文字列の文字数を数える関数です。
mb_strlen関数は日本語などのマルチバイト文字列の文字数を数える関数です。
strlen関数はバイト数を習得する関数です。
文字エンコーディングは省略できます。
文字エンコーディングとはどの文字コードでこの関数を実行するのかを指定します。
では例をみてみましょう。 結果は「10個」 です。
結果は「10個」 です。
 mb_convert_kana関数は全角英数字を半角に変えたり、半角英数字を全角に変えたり、かな文字を全角カナや半角カナに変換することができます。
mb_convert_kana関数は全角英数字を半角に変えたり、半角英数字を全角に変えたり、かな文字を全角カナや半角カナに変換することができます。
エンコーディングは省略できます。

 では例をみてみましょう。
では例をみてみましょう。 半角英数字を全角に変換しますので変換オプションはAを使います。
半角英数字を全角に変換しますので変換オプションはAを使います。
結果は以下の通りです。
「akasaka123」
次の例をみてみましょう。
 では説明を始めます。
では説明を始めます。
![]() はフェラーリという全角カタカナを半角カタカナに変換してますので、結果は
はフェラーリという全角カタカナを半角カタカナに変換してますので、結果は![]() です。
です。
![]() はランボルギーニという全角カタカナを全角ひらがなに変換してますので、結果は
はランボルギーニという全角カタカナを全角ひらがなに変換してますので、結果は![]() です。
です。
![]() はふらのという全角ひらがなを半角カタカナに変換してますので、結果は
はふらのという全角ひらがなを半角カタカナに変換してますので、結果は![]() です。
です。
カテゴリー