この章では正規表現について説明します。
ショッピングサイトでお買い物をする時、電子メールや住所などの個人情報を入力することがありますが、電子メールや郵便番号などが正しく入力されているのかを調べる必要があります。
そのような時に正規表現を使います。
正規表現とは電子メールや郵便番号などの文字の並びをパターン化して、正規表現特有の記号で表現する形式です。
では例を見てみましょう。 正規表現にはメールアドレスなどの文字列が正規表現のパターンに一致するかを調べるためにpreg_match関数が用意されています。
正規表現にはメールアドレスなどの文字列が正規表現のパターンに一致するかを調べるためにpreg_match関数が用意されています。
preg_match関数は一致した回数を返すのですが、一回目で一致した時点で一致するかどうかのチェックを止めるので,マッチしたのならば1を、マッチしなかったのならば0を返します。
では例をみてみましょう。
 この例は
この例は![]() の中に正規表現である
の中に正規表現である![]() と言う文字列が含まれているかどうか調べています。
と言う文字列が含まれているかどうか調べています。
このように正規表現パターン文字列は![]() で囲みます。
で囲みます。
この例では![]() の中の
の中の![]() にマッチしているので
にマッチしているので![]() を出力します。
を出力します。
例えば、$kensaku の中身を![]() のように変更した場合には正規表現の
のように変更した場合には正規表現の![]() にマッチしません。
にマッチしません。
また、$kensaku の中身が![]() と言うように空白が含まれていても、正規表現の
と言うように空白が含まれていても、正規表現の![]() にマッチしません。
にマッチしません。
このように正規表現というのはチェックする機能を持っています。
電話番号などが正しく入力されているのかを簡単にチェックできますので、とても便利な機能です。
次の例をみてみましょう。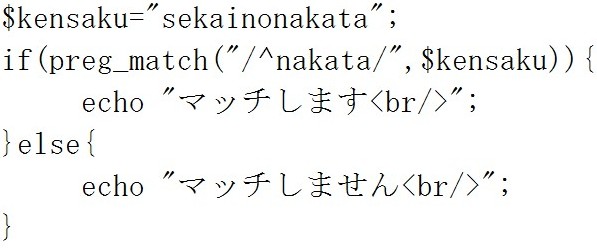 正規表現において
正規表現において![]() の中の
の中の![]() は、文字の初めにマッチするかどうかを調べる時に使います。
は、文字の初めにマッチするかどうかを調べる時に使います。
この例の場合は![]() は文字の初めにはないので、マッチしません。
は文字の初めにはないので、マッチしません。
![]() のように
のように![]() が前にあればマッチします。
が前にあればマッチします。
![]() をメタ文字と言います。
をメタ文字と言います。
次の例をみてみましょう。 正規表現において
正規表現において![]() は、文字の終わりにマッチするかどうかを調べる時に使うメタ文字です。
は、文字の終わりにマッチするかどうかを調べる時に使うメタ文字です。
この例の場合は![]() は文字の終わりにはないので、マッチしません。
は文字の終わりにはないので、マッチしません。
![]() であればマッチします。
であればマッチします。
次の例をみてみましょう。 正規表現パターンの初めに
正規表現パターンの初めに![]() 終わりに
終わりに![]() を付けると
を付けると![]() のみにマッチしますが、この例の場合は$kensakuの中には
のみにマッチしますが、この例の場合は$kensakuの中には![]() が含まれているのでマッチしません。
が含まれているのでマッチしません。
次の例をみてみましょう。 「”/sekai[0-9]/”」は
「”/sekai[0-9]/”」は![]() という文字列とsekaiの後の最初の1文字が0から9までの数字のうちどれか1つにマッチするかどうかを調べます。
という文字列とsekaiの後の最初の1文字が0から9までの数字のうちどれか1つにマッチするかどうかを調べます。
パターンのなかの![]() にはマッチさせたい文字列や数字を並べます。
にはマッチさせたい文字列や数字を並べます。
この例では![]() の後ろの1文字目が0から9までの数字かどうかを調べるので
の後ろの1文字目が0から9までの数字かどうかを調べるので![]() と書いています。
と書いています。
![]() は0から9までという意味です。
は0から9までという意味です。
![]() を書き換えると
を書き換えると![]() になりますので、以下のように書いても同じ意味です。
になりますので、以下のように書いても同じ意味です。 例の場合は「sekai」にはマッチしているので、後は
例の場合は「sekai」にはマッチしているので、後は![]() の中を判定するのですが、
の中を判定するのですが、![]() の後の最初の1文字が数字の5なのでマッチします。
の後の最初の1文字が数字の5なのでマッチします。 なぜなら、パターンは
なぜなら、パターンは![]() であり、
であり、![]() の後の最初の1文字は数字の5だからです
の後の最初の1文字は数字の5だからです
 の場合、sekaiの次の文字がnで0から9までの数字ではないのでマッチしません。
の場合、sekaiの次の文字がnで0から9までの数字ではないのでマッチしません。
次の例をみてみましょう。 「sekai[0-9]{7}」は
「sekai[0-9]{7}」は![]() の後ろに0から9までの数字が7桁含まれているかどうかを判定しています。
の後ろに0から9までの数字が7桁含まれているかどうかを判定しています。
![]() の中にはマッチさせたい桁数を3桁なら3、5桁なら5と指定してください。
の中にはマッチさせたい桁数を3桁なら3、5桁なら5と指定してください。
$kensaku2の中の数字は3桁しかないので、マッチしません。
次の例をみてみましょう。 「sekai]の後ろの2から9までの数字が2桁以上7桁以下であるか判定しています。
「sekai]の後ろの2から9までの数字が2桁以上7桁以下であるか判定しています。
この例では2桁以上なのでマッチしますが1桁の場合はマッチしません。
「{2,7}」の中の左辺は始まりの数字で、右辺は終わりの数字で、始まりの数字以上終わりの数字以下繰り返しているかを判定できます。
次の例をみてみましょう。 「sekai」の後ろに
「sekai」の後ろに![]() が付いていますが、これはメタ文字です。
が付いていますが、これはメタ文字です。
このメタ文字は任意の1文字にマッチする機能を持っています。
これは数字でも文字でもなんでもマッチします。
この例ではsekaiの後ろの![]() にマッチしています。
にマッチしています。
しかしこのメタ文字は改行文字にはマッチしませんので注意してください。
次の例をみてみましょう。 正規表現の中でドット「.」そのものにマッチさせたい場合は
正規表現の中でドット「.」そのものにマッチさせたい場合は![]() のようにドットの前に
のようにドットの前に![]() を入れてください。
を入れてください。
「¥」を入れないとメタ文字になってしまいます。
この例ではsekaiの後ろのドットそのものにマッチします。
次の例をみてみましょう。 「[a-zA-Z0-9_]」は英大文字と英小文字、数字,アンダーバーのどれか1文字にマッチするかどうかを調べる時に使います。
「[a-zA-Z0-9_]」は英大文字と英小文字、数字,アンダーバーのどれか1文字にマッチするかどうかを調べる時に使います。
これをメタ文字で表すと![]() です。
です。
つまり、![]() と書いても同じ意味です。
と書いても同じ意味です。
この例ではsekaiのうしろのアンダーバーにマッチしています。
次の例をみてみましょう。 [^0-9]は0から9以外という意味です。
[^0-9]は0から9以外という意味です。
![]() のカッコのなかで
のカッコのなかで![]() を使うと
を使うと![]() という意味になります。
という意味になります。
この例の場合には指定した数字以外の任意の1文字にマッチします。
「^」は、左ブラケットの直後に入れてください。
注意点は[a-z^0-9]というように「^」を先頭ではなくて途中に書くとただ単にキャレットと言う意味になります。
ブラケットを使わないで、![]() のように
のように![]() の中で
の中で![]() を使うと文字の初めにマッチする表現になりますので違いに注意してください。
を使うと文字の初めにマッチする表現になりますので違いに注意してください。
この例の答えは![]() の次の文字が数字なので
の次の文字が数字なので![]() が出力されます。
が出力されます。
[^0-9]を別の表現で表すと![]() になります。
になります。
他の例を以下に紹介します。
「/sekai[^abcd]/」と書けば![]() の次の文字がabcd以外という意味になります。
の次の文字がabcd以外という意味になります。
次の例をみてみましょう。 「?」(メタ文字)の意味は「?」の直前のものが、あってもいいし、なくてもいい、別の表現で言いますと「?」の直前の物が0個か1個という意味です。
「?」(メタ文字)の意味は「?」の直前のものが、あってもいいし、なくてもいい、別の表現で言いますと「?」の直前の物が0個か1個という意味です。
つまり、直前のものが 0 回または1 回出現するものとマッチします。
この例の場合にはeがない状態である![]() でもマッチしますし、eがある状態である
でもマッチしますし、eがある状態である![]() でもマッチします。
でもマッチします。
「”/se?kai/”」は![]() と書き替えても同じ意味になります。
と書き替えても同じ意味になります。
この例では![]() の中の「e」はあってもなくてもいいのでマッチします。
の中の「e」はあってもなくてもいいのでマッチします。
次の例をみてみましょう。 「+」(メタ文字)は「+」の直前のものが1個以上マッチするという意味です。
「+」(メタ文字)は「+」の直前のものが1個以上マッチするという意味です。
つまり、直前のものが 1 回以上の繰り返しをした時にマッチします。
ですのでこの例は「+」の直前の文字「a」が1 回以上の繰り返しをしていないのでマッチしません。
「”/seka+i/”」は![]() と同じ意味です。
と同じ意味です。
「x{n,}」の意味は![]() という意味です。
という意味です。
次の例をみてみましょう。 「*」(メタ文字)は直前のものに0回以上マッチするのかと言う意味です。
「*」(メタ文字)は直前のものに0回以上マッチするのかと言う意味です。
ですので![]() のように「a」があってもなくてもマッチします。
のように「a」があってもなくてもマッチします。
次の例をみてみましょう。 「”/(seki)+/”」のようにカッコで囲んでグループ化してそのグループ化したものに対してのパターンを判定します。
「”/(seki)+/”」のようにカッコで囲んでグループ化してそのグループ化したものに対してのパターンを判定します。
このカッコを外すと直前のiだけが対象になりiの1個以上のマッチを判定することになります。
この例の結果は![]() は1回以上繰り返しているので、
は1回以上繰り返しているので、![]() になります。
になります。
次の例をみてみましょう。 (world|japan)の中の「|」は「もしくは」と言う意味で
(world|japan)の中の「|」は「もしくは」と言う意味で![]() か
か![]() のどれかが当てはまればマッチします。
のどれかが当てはまればマッチします。
英語のorに相当します。
注意点はブランケットの中で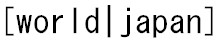 と書いても「もしくは」の意味では使うことが出来ませんので注意してください。
と書いても「もしくは」の意味では使うことが出来ませんので注意してください。
次の例をみてみましょう。 パターン文字列の右下に「i」が付いていますが、これは修飾子といいます。
パターン文字列の右下に「i」が付いていますが、これは修飾子といいます。
これは大文字と小文字を区別しないでマッチングを行います。
例で説明しますと![]() の先頭が大文字で、正規表現の
の先頭が大文字で、正規表現の![]() の先頭は小文字ですが、「i」があるお蔭で
の先頭は小文字ですが、「i」があるお蔭で![]() が出力されます。
が出力されます。
次の例をみてみましょう。 メタ文字「.」は通常は改行文字 にはマッチしませんが,
メタ文字「.」は通常は改行文字 にはマッチしませんが,![]() と言う「修飾子」を付けることによって改行文字を含めてあらゆる文字にマッチさせることが出来ます。
と言う「修飾子」を付けることによって改行文字を含めてあらゆる文字にマッチさせることが出来ます。
![]() のようにiとsを両方指定することも出来ます。
のようにiとsを両方指定することも出来ます。
![]() と順番を変えても動作は同じです。
と順番を変えても動作は同じです。
次の例をみてみましょう。 この例では郵便番号が正しく入力されているかをチェックしています。
この例では郵便番号が正しく入力されているかをチェックしています。
つまり、以下のような意味になります。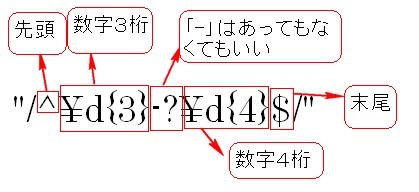 結果は
結果は![]() が出力されます。
が出力されます。
次の例をみてみましょう。 この例では正規表現パターンにマッチしたものを取り出す方法について説明します。
この例では正規表現パターンにマッチしたものを取り出す方法について説明します。
もう一度、preg_match関数の構文を見直してみてください。
第三引数に検索結果が代入される配列という引数がありますので、マッチしたものをこの配列に入れます。
配列$rtの1番前にマッチした文字列の全てが入っていますので, ![]() にはマッチした「320-0906」
にはマッチした「320-0906」
が入っています。
次の例をみてみましょう。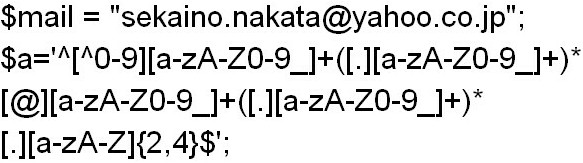
 (紙面の都合で$aの中の正規表現を複数行で書いていますが1行で書いてください)
(紙面の都合で$aの中の正規表現を複数行で書いていますが1行で書いてください)
これはメールアドレスの形式が正しいかどうかを調べる正規表現です。
メールアドレスの形式はある程度決まっているので、その形式をパターン化して、正しいかどうかをチェックすることが出来ます。
これまではパターン文字列は![]() のように直接書いていましたが、この例の場合にはパターン文字列を
のように直接書いていましたが、この例の場合にはパターン文字列を![]() のように変数に入れて使用しています。
のように変数に入れて使用しています。
メールアドレスの正規表現は少し長いですが、少しずつ区切って説明していきます。 パターン文字列の中にカッコで囲まれている箇所がありますが、この箇所をサブマッチパターンといいます。
パターン文字列の中にカッコで囲まれている箇所がありますが、この箇所をサブマッチパターンといいます。
サブマッチした箇所は配列の2番目の要素から順に代入されていきます。
配列の1番目の要素にはマッチした文字列全部が代入されます。
 結果は以下の通りです。
結果は以下の通りです。![]() =>配列の1番目の要素にはマッチした文字列全部が代入されますので、結果は
=>配列の1番目の要素にはマッチした文字列全部が代入されますので、結果は![]() です。
です。![]() =>サブマッチした箇所は配列の前の要素から順に代入されていきますので、二つある中で一番初めの
=>サブマッチした箇所は配列の前の要素から順に代入されていきますので、二つある中で一番初めの![]() のサブマッチパターンにマッチした文字列が
のサブマッチパターンにマッチした文字列が![]() に入っています。
に入っています。
結果は![]() です。
です。![]() =>サブマッチした箇所は配列の前の要素から順に代入されていきますので、二つある中で二番目の
=>サブマッチした箇所は配列の前の要素から順に代入されていきますので、二つある中で二番目の![]() のサブマッチパターンにマッチした文字列が
のサブマッチパターンにマッチした文字列が![]() に入っています。
に入っています。
結果は![]() です。
です。
preg_matchは1回マッチしたら検索を中止しますが、すべてのマッチングの結果を得たい場合はpreg_match_all関数を使ってください。 [マッチした結果を入れる配列]は多次元配列(この本では2次元配列を説明しましたが、原理的には3次元、4次元…..も実現できます。
[マッチした結果を入れる配列]は多次元配列(この本では2次元配列を説明しましたが、原理的には3次元、4次元…..も実現できます。
それを総称して多次元配列と言っています)になります。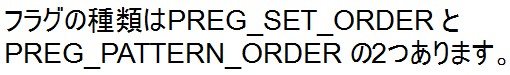 では例をみてみましょう。
では例をみてみましょう。
 (紙面の都合で$aの中の正規表現を複数行で書いていますが1行で書いてください)
(紙面の都合で$aの中の正規表現を複数行で書いていますが1行で書いてください)
ではpreg_match_allについて説明します。
使い方はpreg_matchと同じですが、[マッチした結果を入れる配列]が多次元配列になりますので、結果は以下の通りになります。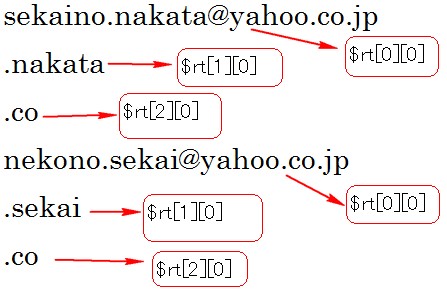 この例は[PREG_PATTERN_ORDERを指定した場合]ですので、連想配列のそれぞれには以下のものが格納されています。
この例は[PREG_PATTERN_ORDERを指定した場合]ですので、連想配列のそれぞれには以下のものが格納されています。
$rt[0][0]にはメールアドレス全体
$rt[1][0]には1番前のサブパターンマッチでマッチした文字列
$rt[2][0] には2番目のサブパターンマッチでマッチした文字
次は[PREG_SET_ORDERを指定した場合]の結果を見てみましょう。
 (紙面の都合で$aの中の正規表現を複数行で書いていますが1行で書いてください)
(紙面の都合で$aの中の正規表現を複数行で書いていますが1行で書いてください)
結果は以下の通りです。
連想配列のそれぞれには以下のものが格納されています。
PREG_PATTERN_ORDERとの違いを確認してください。
$rt[0][0]にはメールアドレス全体
$rt[0][1]には1番前のサブパターンマッチでマッチした文字列
$rt[0][2] には2番目のサブパターンマッチでマッチした文字列
次は文字列の検索と置換を行う関数について説明します。 preg_replace関数は正規表現によって文字列の検索と置換を行う関数です。
preg_replace関数は正規表現によって文字列の検索と置換を行う関数です。
検索や置換の対象となる文字列に対して正規表現のパターンで検索を行い、別の文字列に置換します。
では例をみてみましょう。 以下のように正規表現のパターンにマッチした文字列全体が
以下のように正規表現のパターンにマッチした文字列全体が![]() に入り、そしてカッコで囲まれた1番前のサブマッチパターンにマッチした箇所が
に入り、そしてカッコで囲まれた1番前のサブマッチパターンにマッチした箇所が![]() 、2番目のカッコが
、2番目のカッコが![]() という順番で参照されます。
という順番で参照されます。
対象があれば3番目は![]() 4番目は
4番目は![]() と続きます。
と続きます。
これを後方参照と言います。このようにマッチした箇所を簡単に取り出せるので便利です。 つまり、ここでは正規表現パターンに合致した文字列(この例の場合意にはURL)に対してリンクを張っているわけです。
つまり、ここでは正規表現パターンに合致した文字列(この例の場合意にはURL)に対してリンクを張っているわけです。
この例では「¥0」 の部分つまりURLを取り出して、以下の箇所でリンクを張っています。![]() 結果は以下のようにリンクされたURLが出力されます。
結果は以下のようにリンクされたURLが出力されます。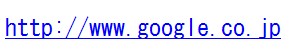






{kind=link}