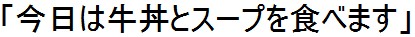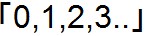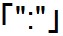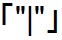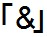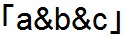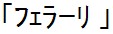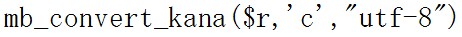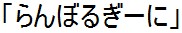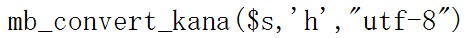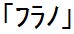この章では文字列に関する関数について説明します。
配列の関数に続いて今度は文字列に関する関数について説明します。
では例をみてみましょう。
結果は![]()
今度は元の文字列に配列を使った例を説明します。
結果は以下の通りです。
z
b
c

では例をみてみましょう。
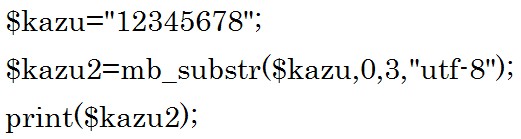
![]()
結果は 「123」 です。
次の例をみてみましょう。
取り出す文字数、文字コードは省略できます。
結果は 「5678」 です。

では例をみてみましょう。
![]()

では例をみてみましょう。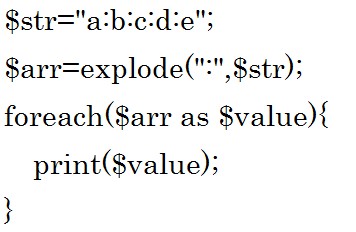
![]()
配列なのでforeachで取り出すことが出来ます。
区切り文字は文字列であれば![]()
![]()
結果は「abcde」です。
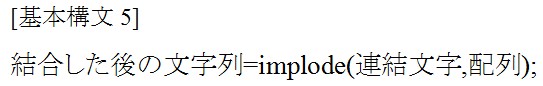

![]()
![]()

長さとはバイト数のことです。
半角英数字は1文字1バイトとして数えています。
おおよそ日本語のようなマルチバイト文字は1文字2バイトですが、文字コードがUTF-8では概ね3バイトで表されます。
つまり、バイト数は、文字コードに依存するので複雑です。
そのような理由から、日本語の文字数を数えたい場合は次に説明します![]()

21バイト
13バイト

strlen関数はバイト数を習得する関数です。
文字エンコーディングは省略できます。
文字エンコーディングとはどの文字コードでこの関数を実行するのかを指定します。
では例をみてみましょう。

エンコーディングは省略できます。



結果は以下の通りです。
「akasaka123」
次の例をみてみましょう。

![]()
![]()
![]()
![]()
![]()
![]()